“How to work with PII data in a modern data stack with dbt?” - different flavors of this question have been asked by data professionals on dbt Discourse, dbt Slack, and other data forums. Users proposed various solutions for PII anonymization, sensitive data separation, and access management. In this post, I’d like to go over some of the ways that this is handled in dbt today, and show you a potential alternative with Immuta to handle sensitive data requirements for organizations that require more granular permission controls.
I write on dataplatformschool.com about new tools that I get exposed to in the modern data stacks. My latest finding - Immuta’s dbt Cloud integration which makes dbt metadata about tables and columns available in Immuta. Then Immuta applies data access policies and allows only legitimate readers to see the data. Based on database technology, Immuta applies different techniques and integration mechanisms to secure Snowflake, Databricks, Azure Synapse, and other sources.
Solving PII requirements with dbt and database permissions
A possible solution to solve sensitive data requirements with dbt might look like this:
- Mark sensitive columns with tags or meta fields (read about differences between meta and tags on dbt Slack)
- Use dbt macros to hash/anonymize data
- Produce PII and non-PII views and/or tables
- Use dbt hooks to control access to the above objects
Read more how GitLab and other companies use a combination of the above steps to solve their requirements.
Also, it’s important to emphasize that implementation details depend on a chosen database technology. Vendors provide different permission models, dynamic data masking (Snowflake, Redshift, Synapse or Databricks), features like secure views, column and row-level access.
The vendor specific access logic can be encapsulated in dbt packages, like dbt_snow_mask (the package contains macros to implement data masking with Snowflake).
Challenges in scaling data access management
Large organizations consist of hundreds of rules and dozens of roles with different privileges. The above presented approaches would lead to data duplication or exclusion of useful data.
Also, PII security and access management is usually not a binary problem. The reality is more complex than show / don’t show PII data, for example:
- Different levels of anonymization required (e.g., hide email, show domain only, show full email)
- Time based access (e.g., sensitive data access allowed only for a project duration)
- Purpose-based access (e.g., PII columns visible for a use case A, but not B)
- Attribute-based access (e.g., access rights based on employee’s location, departments)
- Newly added sensitive column is hidden by default and access needs to be reordered
Last but not least, data access rules should be easily validated and reviewed periodically by data officers. If PII masking logic is hidden in view definitions or dbt macros, non-technical users will struggle to validate its correctness. Hence, a centralized and user-friendly interface might be needed.
Walkthrough of Immuta and dbt Cloud integration
In the example below, you will see how Immuta‘s dbt Cloud integration simplifies PII data masking based on column tags.
There is a customer table with sensitive information (first and last name, email, etc.). Data is coming from a source in its original format (not anonymized).
| c_salutation | c_first_name | c_last_name | c_email_address | … |
|---|---|---|---|---|
| Mrs. | Sara | Long | sara.long@smth | … |
| Mr. | Peter | Krawczyk | p.kraw@cmp | … |
| … | … | … | … | … |
Information available in other tables allows to create a data product with calculated total returned web purchases for each customer. The sensitive columns remain unmasked in the derived table.
| … | c_first_name | c_last_name | c_email_address | ctr_total_return | … |
|---|---|---|---|---|---|
| … | Sara | Long | sara.long@smth | 1245.00 | … |
| … | Peter | Krawczyk | p.kraw@cmp | 0.00 | … |
| … | … | … | … | … |
As per requirement, the end-users should be able to access the output table, but only legitimate users should see PII column entries. Hence, you mark sensitive columns in the schema.yml file using the tags key and setting correct values. “PII” tagged columns should be hidden from non-privileged users.
models:
- name: customer_returns
description: "Table contains customer information with total returned amount"
columns:
- name: c_first_name
tags:
- pii
- name: c_last_name
tags:
- pii
- name: c_email_address
tags:
- pii
- name: ctr_total_return
description: "Calculated total return"
tests:
- not_null
....
Next step - deploy changes to test and eventually production using dbt Cloud jobs.
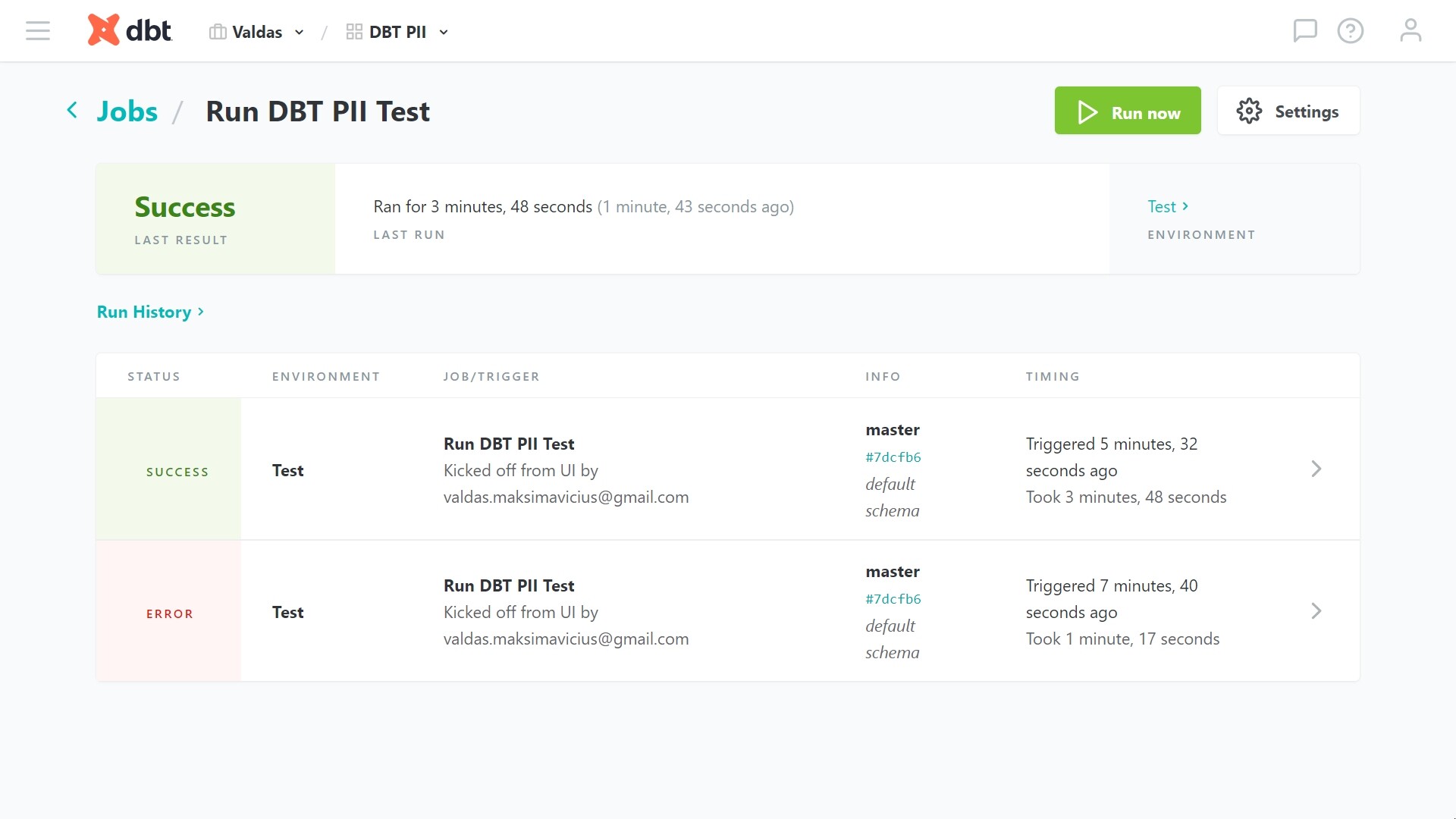
You will use Immuta to grant access to data for end users. First, the integration between Immuta and dbt Cloud has to be enabled in Immuta.

Next, you should connect Immuta and dbt Cloud instances (dbt Cloud user API token and dbt Cloud metadata-only service tokens are required)

It takes a while to pull all metadata information (about sources and produce data models) from dbt Cloud job run.

Immuta also fetches “PII” tag defined in the model’s schema file. They are critical metadata properties, once available in Immuta’s data catalog, can be used to control accesses.

Next, you should create a dynamic policy that can be “written” in plain English. It will mask all “PII” tagged columns using hashing (more algorithms available).
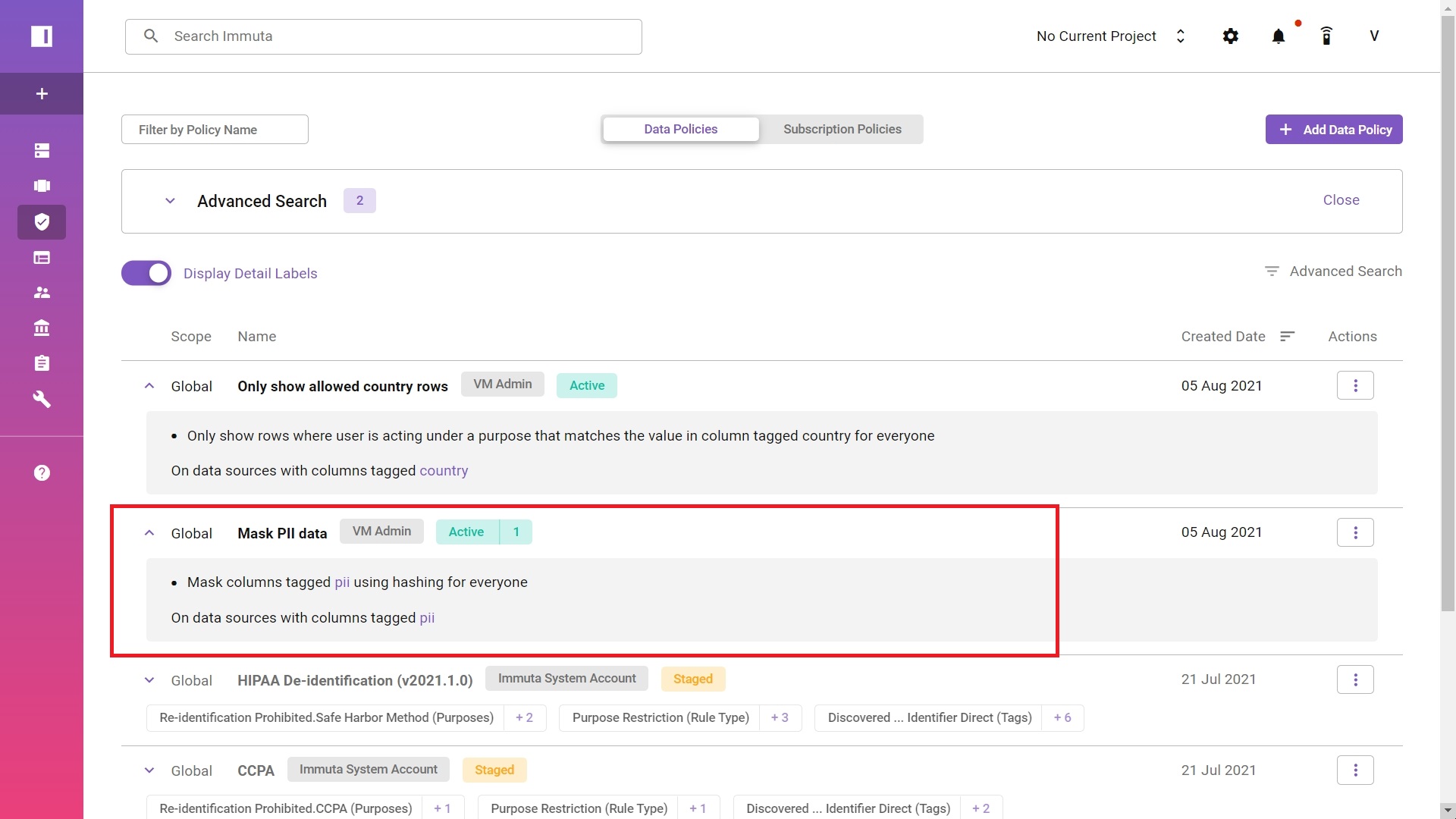
After enabling policies, “PII” tagged columns are successfully masked.
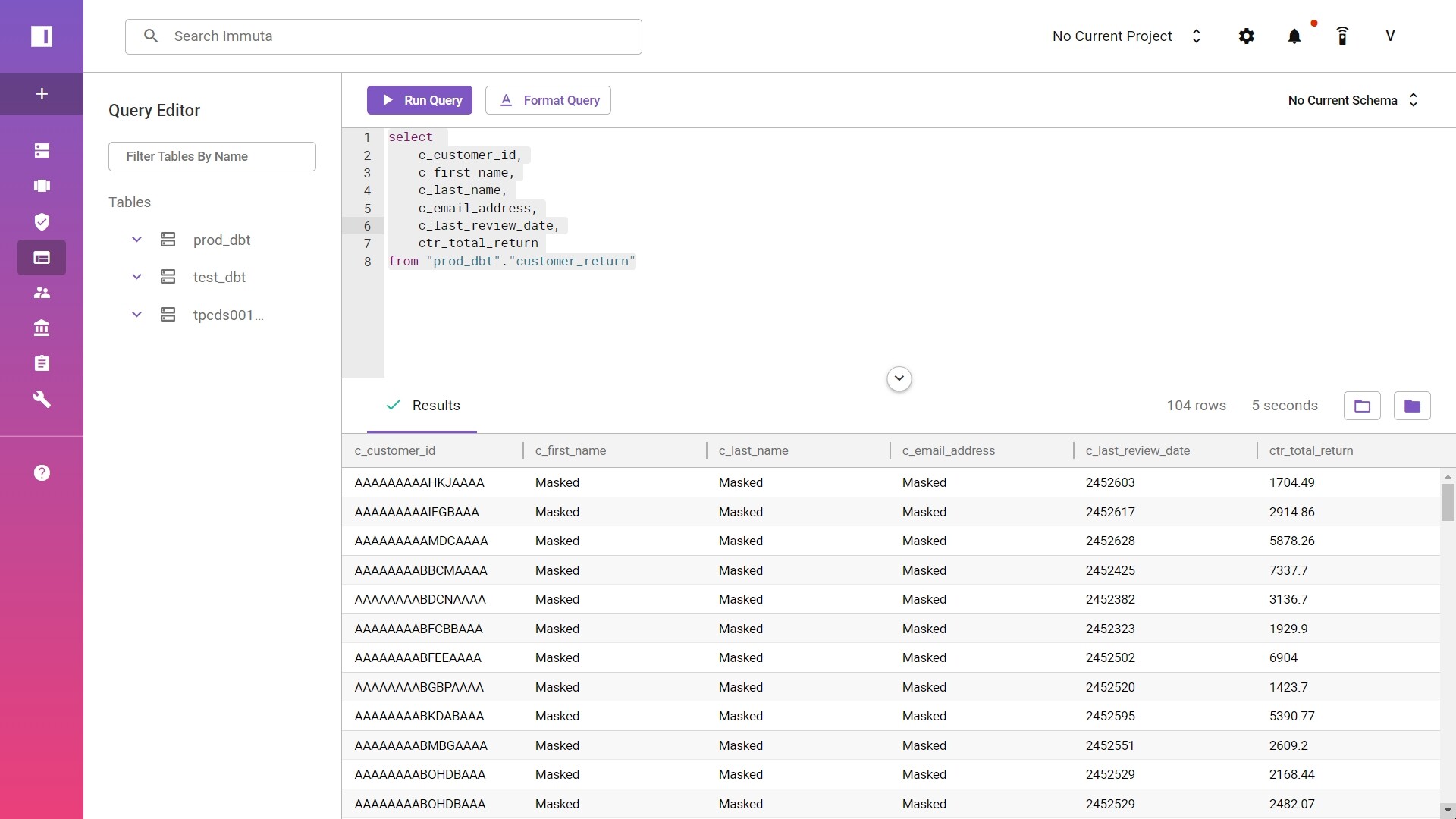
The demo was executed on dbt Cloud, Immuta and Databricks SQL as the underlying compute engine. Immuta also integrates and secures data stored in Snowflake, Redshift, Big Query, Synapse, and many other sources.
Read more about dbt + Immuta