A new pre-release of dbt v0.16.0 (Barbara Gittings) is now available on PyPi and in dbt Cloud. The new and changed functionality in this pre-release is covered below. There are heaps of new features, performance improvements, and bugfixes in this pre-release, and we need your help testing them!
View the Changelog for the full set of changes implemented since 0.15.x
Installation:
# with pip
pip install dbt==0.16.0b3
In dbt Cloud:
Select 0.16.0 beta in the environment of your choice.
If you give the pre-release a spin, please follow up below with a comment indicating which features you tried out and if you had any issues running dbt. If you do encounter an issue with the pre-release, we’ll work to fix them before the final release of dbt v0.16.0 (estimated ~2 weeks from now)
Please note that documentation for the new and changed functionality is coming shortly! I’ll be updating this post with links to the relevant docs as they’re added.
New and changed (highlights):
Core
Add support for a generate_database_name macro
Rationalize csv parsing in seed files. Seed behavior should be much less surprising now
If a seed is configured with custom data types, that column will be parsed as a string to avoid errant agate type inference
Limit the types of date/time formats that are automatically parsed from strings. Sunday will no longer return the first Sunday after 0000-01-01 as before, which is good.
Improve speed of catalog queries (parallelizing smaller queries w/ push-down filter logic). This should ameliorate issues Snowflake and BigQuery users were seeing about compilation memory becoming exhausted, or the information schema returning too much data.
Support tags on sources, columns, and tests, eg:
# schema.yml
version: 2
models:
- name: my_model
columns:
- name: id
tags: ['my_col_tag']
tests:
- relationships:
to: abc
field: other_id
tags: ["my_test_tag"]
----------------------------------------------------
# Run tests tagged with a specific tag
$ dbt test -m tag:my_test_tag
# Run all tests on columns tagged with a specific tag
$ dbt test -m tag:my_col_tag
Docs
Note: These changes are not yet released in the 0.16.0-b3 pre-release, but will be live in dbt 0.16.0-rc1
Support hiding models in the documentation website
Support meta keys in the documentation website
Support documentation on seeds, snapshots, macros, analyses, and custom data tests
Improve/automate dbt deployment flow, so we’ll be deploying many more pre-releases of dbt in the future!
BigQuery
Fix database errors when changing the partitioning or clustering configs for an existing table model
Support a cost-effective merge operation in incremental models and enhanced partition configs (more on this to come!). Example usage:
{{ config(
materialized='incremental',
partition_by={"field": "collector_tstamp", "data_type": "date},
unique_key="event_id"
) }}
select * from snowplow.event
{% if is_incremental() %}
-- _dbt_max_partititon is injected into the query using BQ Scripting
where collector_tstamp > _dbt_max_partition
{% endif %}
Specific questions:
Snowflake users: do you find that startup time is faster than before?
BigQuery users who previously encountered issues with dbt docs generate - are these issues now fixed?
Is anything that was previously working now broken? If so, what?
On dbt run
I’m getting this error for 3 models that have partition configs:
Compilation Error in macro bigquery__get_merge_sql (macros/materializations/merge.sql)
macro 'dbt_macro__bigquery__get_merge_sql' takes not more than 4 argument(s)
> in macro adapter_macro (macros/adapters/common.sql)
> called by macro get_merge_sql (macros/materializations/common/merge.sql)
> called by macro bq_partition_merge (macros/materializations/incremental.sql)
> called by macro materialization_incremental_bigquery (macros/materializations/incremental.sql)
> called by macro bigquery__get_merge_sql (macros/materializations/merge.sql)
I did see the deprecation warnings, but it sounds like dbt would be smart enough to infer the correct partition:
* Deprecation Warning: As of dbt v0.16.0, the `partition_by` config in BigQuery
accepts a dictionary containing `field` and `data_type`.
- Provided partition_by: date(session_start_timestamp_pst)
- dbt inferred: {'field': 'session_start_timestamp_pst', 'data_type':
'timestamp'}
Thanks for the report @claus! Do you know if you have a custom override of bigquery__get_merge_sql in your project? We removed this macro from the dbt-bigquery, so I think that if you’re seeing this error still, it’s because it lives in your project. Let me know if that’s not the case!
@drew definitely didn’t override merge in this or any project…I also just checked that dbt clean doesn’t help here.
Anything else I can do to help debug this?
However, some anecdotal comparisons here show, at least for this table, a slowdown in incremental update processing time, and an increase in bytes processed.
This could be a factor of this table not being that large, so this may get better as we scale, but maybe there is also something wrong in our approach.
We always process the last 3 days, for late arriving event data
Table is partitioned on session_start_timestamp, which is what we use to filter in the incremental where clause
Table size
9.27 GB
Number of rows
3,740,797
Partitioned by
Day
Partitioned on field
session_start_timestamp
The new BQ script looks good to me, it seems to correctly merge on both the unique_key as well as the partition field.
set (dbt_partitions_for_upsert) = (
select as struct
array_agg(distinct date(session_start_timestamp))
from my_project.my_schema.events__dbt_tmp
);
-- 3. run the merge statement
merge into my_project.my_schema.events as DBT_INTERNAL_DEST
using (
select * from my_project.my_schema.events__dbt_tmp
) as DBT_INTERNAL_SOURCE
on date(DBT_INTERNAL_DEST.session_start_timestamp) in unnest(dbt_partitions_for_upsert) and
DBT_INTERNAL_SOURCE.event_id = DBT_INTERNAL_DEST.event_id
dbt 0.15.2
dbt run --target dev -m events
Running with dbt=0.15.2
...
06:41:13 | 1 of 1 OK created incremental model my_schema.events [MERGE (514084) in 66.85s]
dbt run --target dev -m events
Running with dbt=0.16.0-rc2
...
06:43:54 | 1 of 1 OK created incremental model my_schema.events [SCRIPT (4.0 GB processed) in 93.52s]
Ha, @claus that is… not what we want. I can do some digging to see why that would be the case. I can buy that this approach is slower (we run more queries) but I’m shocked that more bytes are processed! I would have though it would be strictly less data scanned in these queries. Can you share your config for this model + a representative example of the incremental predicate for this model?
Can you also try using the (undocumented and beta-ish) insert_overwrite approach outlined here: Feature/bq incremental strategy insert_overwrite by jtcohen6 · Pull Request #2153 · dbt-labs/dbt-core · GitHub. By setting the incremental_strategy to insert_overwrite, dbt will ignore the unique_key (you don’t need to provide one) and insert replace records in the destination table based on the partitioning config. Definitely do this in dev, as it’s destructive and not well documented at the moment (but that will change soon!)
Thanks @drew! I have a hunch that at this scale, the overhead of running the additional queries so far outweighs the benefits of new merge strategy. I will reach out on Slack re: config details.
I’ll also check out the insert overwrite approach this weekend and will let you know.
For those following along at home, @claus and I managed to get to the bottom of this, and I wrote up an issue here. Really exciting stuff! BigQuery is smarter than we are, sometimes
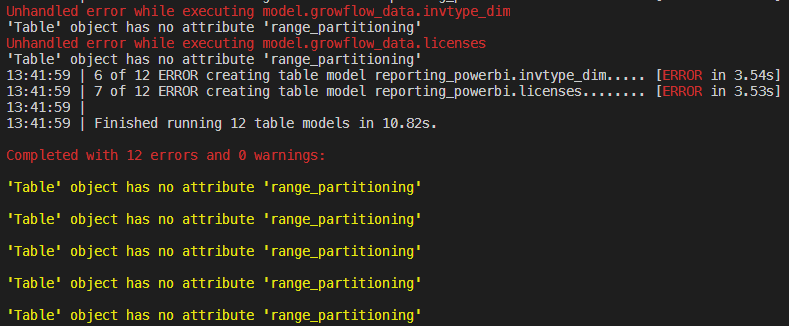
On dbt run of an already-existing relatively plain set of output tables. dbt is throwing the same error for every output. "Table object has no attribute range_partitioning". Any idears??
Hey @warpraptor - I played around with this today and I wasn’t able to replicate the behavior that you’re seeing. Is there any chance you may have an out-of-date version of google-cloud-bigquery? You can check with: